Per my earlier note, I have evaluated my feelings on the units of REST:
1. An architecture is defined by its constraints - Strongly Support
2. Separate client from server - Strongly Support
3. The client / server relationship must remain stateless - Support
4. The client must be able to cache data - Support
5. Uniform Interface - Support
5.1 Identification of Resources - Strongly Support
5.2 Manipulation of Resources through Representations - Strongly Support
5.3 Self Descriptive Messages - Strongly Support
5.4 Hypermedia as the engine of application state - Support
6. Layered System - Support
7. Code on Demand - Don't Support
REST is a single candidate architecture. And an architecture must be evaluated on the whole, rather than the individual parts. Fielding does a great job of stating that every decision in the candidate architecture has trade-offs. He further identifies the applicability of the architecture (distributed systems, system 'feels' stateless, desire to scale, desire to evolve, etc.) Like all candidate architectures, one can only evaluate the architecture against a problem that you are trying to solve. REST by itself can not be evaluated, only evaluated as a candidate solution to a pre-identified problem.
What was interesting to me was the lack of association between REST and HTTP, or more precisely the 'verbs' of HTTP. Instead, Fielding places significant attention on the need to use Resources (think URI), Self Descriptive Messages (think XML), but does imply that a generic interface is required. Somehow... I find myself agreeing with Fielding but disagreeing with many RESTifarians (I'm not sure how this is possible). Fielding suggests a "a uniform interface between components ", however he never mandates what that interface should be - only stating the characteristics. However, I find significant 'folklore' stating that the interface is, "...defined completely and solely by the specified semantics of HTTP, i.e. GET / PUT / POST, etc." (Jeff Bone) He continues to argue, "*there are no applications you can think of which cannot be made to fit into the GET / PUT / POST / resources / representations model of the world!*" The only issue I have is his term "made to fit" - meaning, what was the price of 'making something fit'?
So, with all of this said, where am I landing?
1. REST is a great example of a candidate architecture and should be evaluated based on the problem at hand.
2. REST doesn't dictate HTTP or the HTTP verbs and this is a good thing.
3. REST does state that the interface should be uniform, and this too is a good thing.
4. The base HTTP application semantics can be 'forced' to solve any problem, they just aren't always a good fit.
5. Additional exercises should be performed to document how many RPC style verbs would be translated into a more REST-stlye. Verbs that don't translate shouldn't be forced to fit, rather new verbs should be introduces as part of the first-order vocabulary.
Friday, April 30, 2004
Thursday, April 29, 2004
Tim Bray on things
Tim is now at Sun :-) and has new things to say.
1. He doesn't like composable message architectures. He doesn't like describing the resolution to non-functional requirements of distributed computing via specifications because it is hard. In my opinion, you either specify your separation of concerns with specifications or make them proprietary. I lean towards specifications. Also, the solution will utilize a building block approach or a big-bang approach. Your call. I prefer building block.
2. He doesn't like automated service discovery (UDDI). I think he misunderstood what UDDI was all about. That's ok, many people do - it is a design time service, not a run time. Throw away the "automated" part and you're a lot closer.
3. He doesn't like declarative application building. He mentions BPEL and ws-chor as examples of this - unfortunately neither of them are valid examples. Actually, I kind of wish they were! Declarative approaches for state based decision making and distributed invocation has a real place in software development.
4. He doesn't like leaky abstractions. Me either, but unfortunately he doesn't give an example.
5. He's concerned about the standards process. Perhaps the new Sun employee should take a look at the JSR process :-)
6. He's concerned that we aren't making it simple enough. Here he has a decent point - it is complicated. Could it be simplified? Sure, throw away functionality and we can simplify it. Keep in things like reliable messaging, self-contained enveloping, trust, authentication, multiple levels of transactions, etc... yea, you can make it as simple as you'd like!
Welcome to web services :-)
1. He doesn't like composable message architectures. He doesn't like describing the resolution to non-functional requirements of distributed computing via specifications because it is hard. In my opinion, you either specify your separation of concerns with specifications or make them proprietary. I lean towards specifications. Also, the solution will utilize a building block approach or a big-bang approach. Your call. I prefer building block.
2. He doesn't like automated service discovery (UDDI). I think he misunderstood what UDDI was all about. That's ok, many people do - it is a design time service, not a run time. Throw away the "automated" part and you're a lot closer.
3. He doesn't like declarative application building. He mentions BPEL and ws-chor as examples of this - unfortunately neither of them are valid examples. Actually, I kind of wish they were! Declarative approaches for state based decision making and distributed invocation has a real place in software development.
4. He doesn't like leaky abstractions. Me either, but unfortunately he doesn't give an example.
5. He's concerned about the standards process. Perhaps the new Sun employee should take a look at the JSR process :-)
6. He's concerned that we aren't making it simple enough. Here he has a decent point - it is complicated. Could it be simplified? Sure, throw away functionality and we can simplify it. Keep in things like reliable messaging, self-contained enveloping, trust, authentication, multiple levels of transactions, etc... yea, you can make it as simple as you'd like!
Welcome to web services :-)
RESTifarian?
Mark Baker declared that I was on the way to enlightenment (AKA, seeing things his way).
You know, I'm not sure if I am a RESTifarian.
When I first saw this:
http://www.extremeprogramming.org/rules.html I used it as a tool to determine what components of XP I believed in. It is tough to say, "Yea, I am an XP guy or Yea, I'm a RESTifarian". I've looked at some of the REST wiki's out there and I haven't found the simple list of rules and guidelines.
What I'd like to be able to do is say, "I support RESTifarian rules/practices 3, 5, 9, 11 and 14."
Perhaps if one of the REST supporters would give me the discrete rules for REST, I could more clearly state my opinion.
-------
Side note:
The XP guys did a great job. For the record, I'm not an XP'er. I've worked too many huge projects. Here is my stance:
Planning
User stories are written. - Support
Release planning creates the schedule.- Unsure
Make frequent small releases. - Strongly Support
The Project Velocity is measured. - Unsure
The project is divided into iterations. - Strongly Support
Iteration planning starts each iteration. - Strongly Support
Move people around. - Support
A stand-up meeting starts each day. - Partially Support
Fix XP when it breaks. - Strongly Support
Design
Simplicity. - Don't Support
Choose a system metaphor. - Don't Support
Use CRC cards for design sessions. - Support for OO systems
Create spike solutions to reduce risk. - Strongly Support
No functionality is added early. - Don't Support
Refactor whenever and wherever possible. - Partially Support
Code
The customer is always available. - Unrealistic - Don't Support
Code must be written to agreed standards. - Support
Code the unit test first. - Partially Support
All production code is pair programmed. - Don't Support
Only one pair integrates code at a time. - Don't Support
Integrate often. - Fully Support
Use collective code ownership. - Partially Support
Leave optimization till last. - Don't Support
No overtime. - Don't Support
Testing
All code must have unit tests. - Partially Support
All code must pass all unit tests before it can be released. - Support
When a bug is found tests are created. - Support
Acceptance tests are run often and the score is published. - Fully Support
No, I'm not an XP'er. I think they had some great ideas - but no, I didn't just close my eyes and say all of them were good ideas and jump on board. Am I a RESTifarian? Give me the tools to evaluate and I'll let you know.
You know, I'm not sure if I am a RESTifarian.
When I first saw this:
http://www.extremeprogramming.org/rules.html I used it as a tool to determine what components of XP I believed in. It is tough to say, "Yea, I am an XP guy or Yea, I'm a RESTifarian". I've looked at some of the REST wiki's out there and I haven't found the simple list of rules and guidelines.
What I'd like to be able to do is say, "I support RESTifarian rules/practices 3, 5, 9, 11 and 14."
Perhaps if one of the REST supporters would give me the discrete rules for REST, I could more clearly state my opinion.
-------
Side note:
The XP guys did a great job. For the record, I'm not an XP'er. I've worked too many huge projects. Here is my stance:
Planning
User stories are written. - Support
Release planning creates the schedule.- Unsure
Make frequent small releases. - Strongly Support
The Project Velocity is measured. - Unsure
The project is divided into iterations. - Strongly Support
Iteration planning starts each iteration. - Strongly Support
Move people around. - Support
A stand-up meeting starts each day. - Partially Support
Fix XP when it breaks. - Strongly Support
Design
Simplicity. - Don't Support
Choose a system metaphor. - Don't Support
Use CRC cards for design sessions. - Support for OO systems
Create spike solutions to reduce risk. - Strongly Support
No functionality is added early. - Don't Support
Refactor whenever and wherever possible. - Partially Support
Code
The customer is always available. - Unrealistic - Don't Support
Code must be written to agreed standards. - Support
Code the unit test first. - Partially Support
All production code is pair programmed. - Don't Support
Only one pair integrates code at a time. - Don't Support
Integrate often. - Fully Support
Use collective code ownership. - Partially Support
Leave optimization till last. - Don't Support
No overtime. - Don't Support
Testing
All code must have unit tests. - Partially Support
All code must pass all unit tests before it can be released. - Support
When a bug is found tests are created. - Support
Acceptance tests are run often and the score is published. - Fully Support
No, I'm not an XP'er. I think they had some great ideas - but no, I didn't just close my eyes and say all of them were good ideas and jump on board. Am I a RESTifarian? Give me the tools to evaluate and I'll let you know.
Wednesday, April 28, 2004
Inserting Nouns into the Service Network
For the last 6 months I've been investigating the separation of nouns and adjectives from the verbs and adverbs. For those that don't follow my blog on a regular basis, here is a quick summary:
Nouns are people, places and things - in the software world they are our domain entities (User, Invoice, etc.) - and adjectives are the properties that describe the nouns. In the J-world we used Java classes to describe them - in the W-world we use XML schemas.
Verbs are the actions. Actions have (at least) two forms: technical (insert, update, delete, publish, etc.) and domain or business specific (ship, pack, etc.).
Technical verbs often act the same way on any given noun. Why is this important? Imagine walking into an enterprise with a set of nouns on a floppy disk. The company already has a service network in place. This ServiceNet is composed of 12 servers (portal, database, security, etc.) and runs 46 services. Each server has the capability of 'listening for new nouns' and a 'registration service' has the responsibility of: 1. Notifying the servers of newly registered nouns and 2. Notifying the servers of newly registered servers.
Ok, we just moved into a world where the network is aware of the network. No magic, just simple registration. What gets interesting is when nouns have 'default implementations' of a verb on a server. And surprisingly, you will find that this is possible and beneficial. If I add a new noun to the ServiceNet will it likely have security permissions? Will it need to be stored? Will it be viewed? Should I role all of this code by hand? Again, the goal isn't to perform magic - it is to create a network programming model where we think more about how to create smart verbs and dumb nouns. The servers are slowly given the ability to interrogate each other and eventually a common set of functions is factored out of the servers and dropped into the network.
I'm convinced that service oriented programming has the potential to get absolutely unmanageable. I talk with customers every day - they almost always start the conversation by bragging about the number of services that they have. Every time I hear this I think "Oh my God, what a maintenance nightmare! And they've only begun." In Schneider-land, the goal is to go for the smallest number of services, with the highest amount of reuse. Figuring out how to do this is a bitch.
Going from Services to the ServiceNet
The first step that I recommend is to take a look at all of the operations on all of your wsdls. Categorize what you already have (VerbOnly, VerbNoun, VerbMechanism, other). Then, determine if you could have made more re-usable services. What would they look like? Create a spreadsheet with the verbs as rows and the nouns as columns. The cells (or intersection points) are the realization of the VerbNoun. Beware of verb synonyms, or made up verbs (verbs that are really nouns). What is the smallest number of verbs you require to fulfill your needs?
Nouns are people, places and things - in the software world they are our domain entities (User, Invoice, etc.) - and adjectives are the properties that describe the nouns. In the J-world we used Java classes to describe them - in the W-world we use XML schemas.
Verbs are the actions. Actions have (at least) two forms: technical (insert, update, delete, publish, etc.) and domain or business specific (ship, pack, etc.).
Technical verbs often act the same way on any given noun. Why is this important? Imagine walking into an enterprise with a set of nouns on a floppy disk. The company already has a service network in place. This ServiceNet is composed of 12 servers (portal, database, security, etc.) and runs 46 services. Each server has the capability of 'listening for new nouns' and a 'registration service' has the responsibility of: 1. Notifying the servers of newly registered nouns and 2. Notifying the servers of newly registered servers.
Ok, we just moved into a world where the network is aware of the network. No magic, just simple registration. What gets interesting is when nouns have 'default implementations' of a verb on a server. And surprisingly, you will find that this is possible and beneficial. If I add a new noun to the ServiceNet will it likely have security permissions? Will it need to be stored? Will it be viewed? Should I role all of this code by hand? Again, the goal isn't to perform magic - it is to create a network programming model where we think more about how to create smart verbs and dumb nouns. The servers are slowly given the ability to interrogate each other and eventually a common set of functions is factored out of the servers and dropped into the network.
I'm convinced that service oriented programming has the potential to get absolutely unmanageable. I talk with customers every day - they almost always start the conversation by bragging about the number of services that they have. Every time I hear this I think "Oh my God, what a maintenance nightmare! And they've only begun." In Schneider-land, the goal is to go for the smallest number of services, with the highest amount of reuse. Figuring out how to do this is a bitch.
Going from Services to the ServiceNet
The first step that I recommend is to take a look at all of the operations on all of your wsdls. Categorize what you already have (VerbOnly, VerbNoun, VerbMechanism, other). Then, determine if you could have made more re-usable services. What would they look like? Create a spreadsheet with the verbs as rows and the nouns as columns. The cells (or intersection points) are the realization of the VerbNoun. Beware of verb synonyms, or made up verbs (verbs that are really nouns). What is the smallest number of verbs you require to fulfill your needs?
Monday, April 26, 2004
Custom Metadata
I was just talking with one of my CTO buddies. He was bragging that implementing his software product at a client site requires no custom code. I paused for a moment and asked, "Does it require custom metadata?" To which he answered, "Yes, and it has a nice front-end to enter it in."
My first thought was that he was just pushing the problem from one location to another. But for some reason, it does feel better pushing the problem from code to metadata, but I'm not entirely sure why. I like the idea of not compiling everything (a benefit of metadata). I also like the idea of having domain constraints on the data being entered (versus 3rd gen languages). I guess that a system that embraces MOF/MDA/metadata concepts requires less in-depth expertise. In essence, the expertise is built into the framework, enabling a 'paint-by-number' approach to recurring pattern based problem solving (resources require less training, thus less expensive).
I'd love to hear what you think the advantages to a metadata driven approach are. Blog it. Link to this. Click through once. I'll repost referers.
My first thought was that he was just pushing the problem from one location to another. But for some reason, it does feel better pushing the problem from code to metadata, but I'm not entirely sure why. I like the idea of not compiling everything (a benefit of metadata). I also like the idea of having domain constraints on the data being entered (versus 3rd gen languages). I guess that a system that embraces MOF/MDA/metadata concepts requires less in-depth expertise. In essence, the expertise is built into the framework, enabling a 'paint-by-number' approach to recurring pattern based problem solving (resources require less training, thus less expensive).
I'd love to hear what you think the advantages to a metadata driven approach are. Blog it. Link to this. Click through once. I'll repost referers.
Saturday, April 24, 2004
Is Java an Interchange Format?
So, Microsoft believes that BPEL is an interchange format. It occurred to me that they likely perceive Java as an interchange format as well. If one really, really, really wanted to... you could take C# code, convert it to Java, then convert it into VB.Net. Yes, yes - Java is an interchange format!! I don't know why that didn't occur to me earlier. And all this time I've thought of Java as a programming language.
I'm such a fool. Officially, an 'interchange format' is anything that can be used as a temporary place holder while being 'upgraded' to the Microsoft format (X/Langs, C#, etc.)
Top Ten Interchange Formats (Microsoft perspective):
1. Java
2. BPEL
3. C
4. Perl
5. Python
6. Perl
7. C++
8. JavaScript
9. Haskell
10. Ruby
;-)
I'm such a fool. Officially, an 'interchange format' is anything that can be used as a temporary place holder while being 'upgraded' to the Microsoft format (X/Langs, C#, etc.)
Top Ten Interchange Formats (Microsoft perspective):
1. Java
2. BPEL
3. C
4. Perl
5. Python
6. Perl
7. C++
8. JavaScript
9. Haskell
10. Ruby
;-)
Thursday, April 22, 2004
BPEL4XLang, BPEL4Java BPEL4*
It has been an interesting week in the land of BPEL.
For starters, Microsoft has been in a bit of a predicament. In August of 2002, Microsoft came out saying that they were going to deprecate their proprietary process language (X/Lang) in favor of a new open process language called BPEL. Well, Microsoft missed a couple of ship dates on their BizTalk product and eventually shipped their BizTalk 2004 with X/Lang. In order to save face, they created a mechanism to import and export portions of their X/Lang scripts in BPEL format. Now, Microsoft is saying that oh... the Business Process Execution Language isn't really an execution language - get this - it's an interchange format! Brilliant.
Now, depending on who you talk to at IBM you may find that BPELJ is a good thing. Although, some of the product groups were quite surprised to see the research guys published a white paper on the topic. Interesting. Well, it is worse. In addition to WSFL, BPEL, BPELJ, and the new JSR207, it appears as though IBM is considering additional process languages related to the Rational line of products that are more closely tied to UML. Brilliant.
Well, BEA not wanting to be 'out-dumbed' by MS or IBM has decided to throw more effort at BPELJ, and whine about the lack of progress on JSR207. As one of the BEA insider told me, "BEA is a Java company, not a web services company." What this implies is that BEA is having a hard time dealing with a 'service oriented language' like BPEL in their object-oriented, java-based platform.
So, what can we expect? Here are my predictions:
1. BPEL continues to move forward and serves as the primary foundational technology for executable business process descriptions.
2. A variant of BPELJ becomes JSR207.
3. Microsoft never budges off of X/Lang as their base language
4. The OMG guys create an enhanced Activity Diagram that is 'close enough' to stubbing out BPEL.
Next question: Is this good?
Yes. It is expected that MS will do things their own way - Microsoft will create whatever technology that they need to make things easy for their customers - sure, it will largely lock them in, but most Microsoft shops already know that they're locked in - otherwise they'd be Java shops.
And it is expected that IBM/BEA will bypass the JSR process to expedite a new Java-friendly implementation that Sun will end up incorporating into J2EE. Sun will grumble, eventually adopt it and then find a way to lose money on it.
Last question: What will OpenStorm do?
[coming soon...]
For starters, Microsoft has been in a bit of a predicament. In August of 2002, Microsoft came out saying that they were going to deprecate their proprietary process language (X/Lang) in favor of a new open process language called BPEL. Well, Microsoft missed a couple of ship dates on their BizTalk product and eventually shipped their BizTalk 2004 with X/Lang. In order to save face, they created a mechanism to import and export portions of their X/Lang scripts in BPEL format. Now, Microsoft is saying that oh... the Business Process Execution Language isn't really an execution language - get this - it's an interchange format! Brilliant.
Now, depending on who you talk to at IBM you may find that BPELJ is a good thing. Although, some of the product groups were quite surprised to see the research guys published a white paper on the topic. Interesting. Well, it is worse. In addition to WSFL, BPEL, BPELJ, and the new JSR207, it appears as though IBM is considering additional process languages related to the Rational line of products that are more closely tied to UML. Brilliant.
Well, BEA not wanting to be 'out-dumbed' by MS or IBM has decided to throw more effort at BPELJ, and whine about the lack of progress on JSR207. As one of the BEA insider told me, "BEA is a Java company, not a web services company." What this implies is that BEA is having a hard time dealing with a 'service oriented language' like BPEL in their object-oriented, java-based platform.
So, what can we expect? Here are my predictions:
1. BPEL continues to move forward and serves as the primary foundational technology for executable business process descriptions.
2. A variant of BPELJ becomes JSR207.
3. Microsoft never budges off of X/Lang as their base language
4. The OMG guys create an enhanced Activity Diagram that is 'close enough' to stubbing out BPEL.
Next question: Is this good?
Yes. It is expected that MS will do things their own way - Microsoft will create whatever technology that they need to make things easy for their customers - sure, it will largely lock them in, but most Microsoft shops already know that they're locked in - otherwise they'd be Java shops.
And it is expected that IBM/BEA will bypass the JSR process to expedite a new Java-friendly implementation that Sun will end up incorporating into J2EE. Sun will grumble, eventually adopt it and then find a way to lose money on it.
Last question: What will OpenStorm do?
[coming soon...]
Monday, April 19, 2004
MS Posts Infopath to BizTalk Examples
Scott Woodgate has posted some examples of Infopath using orchestrations. However, I busted open the orchestration file and I'm having a hard time understand this one line of code....
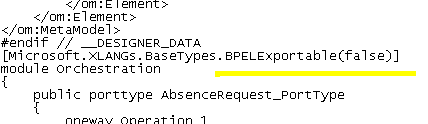
Hmmm... XLang/S.... BPEL export = False? What does that line do?
Hmmm... XLang/S.... BPEL export = False? What does that line do?
Sunday, April 18, 2004
More on UDDI
Jeff,
I just read your blog entry on this, and it's totally in harmony with my own thoughts on the matter. Until a few weeks ago I was in charge of directing the UDDI pilot->implementation programme for [a major investment bank], and we've pulled the plug on it because the whole t-Model thing is just far too complicated to be used in any meaningful way by the constituency that needs it.
We're now planning on building a service registry around an XML metadata store, and will probably go for an XQuery interface as the primary service discovery mechanism. We may keep what I've been terming a 'naive UDDI'
interface for compatibility with existing tools etc., but the long term hope is that we can throw this back over the wall to then vendors (and standards bodies) as something will need to replace UDDI in the web services unholy trinity
--
Chris Swan
Now Stefan states, "I have since come to the conclusion that all this taxonomy and categorization stuff is actually pretty ingenious." Stefan, I agree in a computer science kind-of-way it is ingenious. However, most people just want to quickly store, index or retrieve "Service Oriented Metadata". People don't like taxonomies or t-models.
UDDI was largely designed for external use (the UBR); the use cases that is supports are so far beyond the use cases that are required for intra-company needs that is quickly becomes too complicated.
I'd love to see someone try to explain to me why UDDI isn't a complete piece of shit. Justify it - I'm listening.
I just read your blog entry on this, and it's totally in harmony with my own thoughts on the matter. Until a few weeks ago I was in charge of directing the UDDI pilot->implementation programme for [a major investment bank], and we've pulled the plug on it because the whole t-Model thing is just far too complicated to be used in any meaningful way by the constituency that needs it.
We're now planning on building a service registry around an XML metadata store, and will probably go for an XQuery interface as the primary service discovery mechanism. We may keep what I've been terming a 'naive UDDI'
interface for compatibility with existing tools etc., but the long term hope is that we can throw this back over the wall to then vendors (and standards bodies) as something will need to replace UDDI in the web services unholy trinity
--
Chris Swan
Now Stefan states, "I have since come to the conclusion that all this taxonomy and categorization stuff is actually pretty ingenious." Stefan, I agree in a computer science kind-of-way it is ingenious. However, most people just want to quickly store, index or retrieve "Service Oriented Metadata". People don't like taxonomies or t-models.
UDDI was largely designed for external use (the UBR); the use cases that is supports are so far beyond the use cases that are required for intra-company needs that is quickly becomes too complicated.
I'd love to see someone try to explain to me why UDDI isn't a complete piece of shit. Justify it - I'm listening.
Saturday, April 17, 2004
The UDDI Failure
SOA is about a triangular relationship - producer, consumer and directory. It seems simple. The UDDI represents the directory leg of the relationship, and in my opinion (and I'm not alone) has been a failure. When most people see UDDI for the first time, they usually ask questions like, "couldn't I just stick this information in a database or in LDAP??"
I recently had a discussion with an architect at a leading online brokerage house. He commented that they had looked at UDDI but thought it was overly complicated while simultaneously delivering a lack of functionality. Wow. Useless and a pain in the ass - that is hard to do. Well, these guys punted on UDDI and spent a day writing a small directory using RESTish terms with easy http access. They are very happy.
I'd like to highlight some alternatives to UDDI - if anyone wants to shoot me a note telling me how you're solving the problem or other alternatives, I'd love to hear from you.
I recently had a discussion with an architect at a leading online brokerage house. He commented that they had looked at UDDI but thought it was overly complicated while simultaneously delivering a lack of functionality. Wow. Useless and a pain in the ass - that is hard to do. Well, these guys punted on UDDI and spent a day writing a small directory using RESTish terms with easy http access. They are very happy.
I'd like to highlight some alternatives to UDDI - if anyone wants to shoot me a note telling me how you're solving the problem or other alternatives, I'd love to hear from you.
Tuesday, April 13, 2004
BPEL versus Vaporware
The majority of Radovan's concerns seem to be around the structure that BPEL enforces. Sometimes this is called a "structured process". These are processes where the actors are given rules and are told not to break the rules. Structured processes exist in every corporation that I've been in.
"Semi-structured processes" are those processes that have 'wiggle room'. That is, they enforce a base structure or flow, but at key points run-time decisions can be made.
"Unstructured processes" are really more about achieving goals via whatever means. Here, the participants, the activities and the order will all change at run-time in order to achieve the end goal. The down side is that this often borders on chaos and has limited repeatability - which is a key driver behind process.
What we are finding is that BPEL can handle virtually every case for 'structured' and 'semi-structured' process descriptions and execution. Unstructured processes usually don't lend themselves well to any kind of 'ordered activity machine'. Rather, these processes are more likely to be executed via 'process liberation' tools like Groove, where the focus is on communication and inter-team task visibility.
I don't fully understand the critiques of BPEL. It really is a powerful language - although I can see if you don't work in it where you might be confused. But... we have a team working on this all day, every day... as does Collaxa, FiveSight, SeeBeyond and a host of other companies.
"Semi-structured processes" are those processes that have 'wiggle room'. That is, they enforce a base structure or flow, but at key points run-time decisions can be made.
"Unstructured processes" are really more about achieving goals via whatever means. Here, the participants, the activities and the order will all change at run-time in order to achieve the end goal. The down side is that this often borders on chaos and has limited repeatability - which is a key driver behind process.
What we are finding is that BPEL can handle virtually every case for 'structured' and 'semi-structured' process descriptions and execution. Unstructured processes usually don't lend themselves well to any kind of 'ordered activity machine'. Rather, these processes are more likely to be executed via 'process liberation' tools like Groove, where the focus is on communication and inter-team task visibility.
I don't fully understand the critiques of BPEL. It really is a powerful language - although I can see if you don't work in it where you might be confused. But... we have a team working on this all day, every day... as does Collaxa, FiveSight, SeeBeyond and a host of other companies.
Monday, April 12, 2004
Agree and Disagree
Read this. Negate virtually every sentence and you will have my view.
Read this. Here, I agree on virtually everything. One thing I'd add is that the DSL is a virtual language - it consists of your base language (like bpel AND all of the services (nouns and verbs) in your enterprise vocabulary. In a manufacturing company, your verbs and nouns will relate to purchasing, picking, packing, shipping, etc. Late binding, loose coupling, interoperable schemas, etc. all create a new meaning for the domain specific language. After you pick a first order DSL, you will spend the next decade creating your second order DSL (the enterprise vocabulary).
Read this. Here, I agree on virtually everything. One thing I'd add is that the DSL is a virtual language - it consists of your base language (like bpel AND all of the services (nouns and verbs) in your enterprise vocabulary. In a manufacturing company, your verbs and nouns will relate to purchasing, picking, packing, shipping, etc. Late binding, loose coupling, interoperable schemas, etc. all create a new meaning for the domain specific language. After you pick a first order DSL, you will spend the next decade creating your second order DSL (the enterprise vocabulary).
Sunday, April 11, 2004
Eric Newcomer from Iona recently stated:
I can't see that the drawing approach will really work. I don't know of any graphical software development tool that has yet to address the entire lifecycle; or that generates code of sufficient quality.
I think it's just a problem that isn't meant to be solved.
Since this statement Eric and Stefan have found some common ground:
-Models can have common ui notation and be graphically driven.
-Models can drive metadata.
-The graphical notation and the resulting metadata are two completely different concepts and should be managed that way.
-XML is a great way to drive a metadata approach.
Here are some additional random thoughts:
-Models and action semantics can create traditional 3GL code, but I'm not sure you want them to.
-Metadata can be interpreted by engines and executed.
-Engines are at the heart of reusable services.
-Nouns translate nicely into metadata.
I can't see that the drawing approach will really work. I don't know of any graphical software development tool that has yet to address the entire lifecycle; or that generates code of sufficient quality.
I think it's just a problem that isn't meant to be solved.
Since this statement Eric and Stefan have found some common ground:
-Models can have common ui notation and be graphically driven.
-Models can drive metadata.
-The graphical notation and the resulting metadata are two completely different concepts and should be managed that way.
-XML is a great way to drive a metadata approach.
Here are some additional random thoughts:
-Models and action semantics can create traditional 3GL code, but I'm not sure you want them to.
-Metadata can be interpreted by engines and executed.
-Engines are at the heart of reusable services.
-Nouns translate nicely into metadata.
Friday, April 09, 2004
OpenStorm Orchestrator Update
Just a quick note - next week we will be making available the 2.1 version of the suite. Updates include:
Studio Update
- Improved wsdl editing
- 'Helper' for specifying duration and deadlines
- 'Helper' for graphically creating correlations
- 'Helper' for rapid message definitions on in-bound and out-bound web service calls
- Full XPath manipulation tool
- 'Helper' for boolean expression building (switch, while)
- Ability to create rapid services (drop either Java or C# code directly into an invoke node and it compiles and deploys the code as a remote web service, then replaces the code with the wsdl that front ends the code).
- New 'Web Service Invoker' tool for calling/testing services
- Canvas supports zoom-in/zoom-out, also has a new 'thumb-nail view'
Java Server Update
- Increased support for variations of the 'assign' tag
- New console with drill down (view by bpel, by instance, by correlation, etc.)
- Reliability upgrade with full state machine persistence (test = pull the power plug, plug it back in)
.Net Server Update
- Reworking web service layer to support latest Microsoft WSE upgrades
- Creating long term architecture for Indigo support
documentation
- New BPEL Programmers Manual
- Packaging WSDOX web service documentation with software
In addition, we've added a couple people to the engineering team so we should be able to move a bit quicker on the 2.2 release.
Studio Update
- Improved wsdl editing
- 'Helper' for specifying duration and deadlines
- 'Helper' for graphically creating correlations
- 'Helper' for rapid message definitions on in-bound and out-bound web service calls
- Full XPath manipulation tool
- 'Helper' for boolean expression building (switch, while)
- Ability to create rapid services (drop either Java or C# code directly into an invoke node and it compiles and deploys the code as a remote web service, then replaces the code with the wsdl that front ends the code).
- New 'Web Service Invoker' tool for calling/testing services
- Canvas supports zoom-in/zoom-out, also has a new 'thumb-nail view'
Java Server Update
- Increased support for variations of the 'assign' tag
- New console with drill down (view by bpel, by instance, by correlation, etc.)
- Reliability upgrade with full state machine persistence (test = pull the power plug, plug it back in)
.Net Server Update
- Reworking web service layer to support latest Microsoft WSE upgrades
- Creating long term architecture for Indigo support
documentation
- New BPEL Programmers Manual
- Packaging WSDOX web service documentation with software
In addition, we've added a couple people to the engineering team so we should be able to move a bit quicker on the 2.2 release.
Monday, April 05, 2004
The Promise
From the forward of, "Business Engineering with Object Technology" by David Taylor:
We stand on the threshold of a new era in business engineering. For the first time in the history of computers, it is now possible to build information systems that directly reflect and expand the way we think about business processes. The critical enabler for this transformation is object technology.
Hmm... sound familiar? Well, once again, we find ourselves on the same ole quest.... to achieve a COmmon Business Oriented Language. Yes, I'm a fan of service oriented-bpm. I believe that we need a new vocabulary... for the last several years we have seen some consistent patterns in enterprise computing:
1. A gradual movement towards specialized verbs (servers/services).
2. A desire to separate the verbs from the adverbs (factor out non-functional requirements).
3. Separating nouns and adjectives from verb implementations (XML Schema vs. classes).
4. Standardize the prepositional phrase (predicate).
5. Create a sentence grammar (composition languages).
The verbs and the nouns that we choose to program our computers is central to productivity. The separation of our terms is essential. Breaking the bad habits of the object oriented verb-noun coupling will be tough. Creating our new vocabulary will be even harder. Finding a single Business Oriented Language may be impossible. Yet, we define our programming model by the means in which we separate our concepts. Moving beyond the standards gook is essential.
Oh, and just for fun - here are the verbs of COBOL: Accept, Add, Alter, Call, Cancel, Close, Compute, Delete, Disable, Display, Divide, Enable, Enter, Exit, Generate, GoTo, If, Initiate, Inspect, Merge, Move, Multiply, Open, Perform, Read, Receive, Replacing, Return, Rewrite, Search, Send, Set, Sort, Start, Stop, String, Subtract, Suppress, Terminate, Unstring, Use_After, Use_For_Debugging, Write
If only COBOL had the verbs 'publish', 'subscribe' and 'transform' ... then it we could have called it the 'COBOL-ESB' ;-)
We stand on the threshold of a new era in business engineering. For the first time in the history of computers, it is now possible to build information systems that directly reflect and expand the way we think about business processes. The critical enabler for this transformation is object technology.
Hmm... sound familiar? Well, once again, we find ourselves on the same ole quest.... to achieve a COmmon Business Oriented Language. Yes, I'm a fan of service oriented-bpm. I believe that we need a new vocabulary... for the last several years we have seen some consistent patterns in enterprise computing:
1. A gradual movement towards specialized verbs (servers/services).
2. A desire to separate the verbs from the adverbs (factor out non-functional requirements).
3. Separating nouns and adjectives from verb implementations (XML Schema vs. classes).
4. Standardize the prepositional phrase (predicate).
5. Create a sentence grammar (composition languages).
The verbs and the nouns that we choose to program our computers is central to productivity. The separation of our terms is essential. Breaking the bad habits of the object oriented verb-noun coupling will be tough. Creating our new vocabulary will be even harder. Finding a single Business Oriented Language may be impossible. Yet, we define our programming model by the means in which we separate our concepts. Moving beyond the standards gook is essential.
Oh, and just for fun - here are the verbs of COBOL: Accept, Add, Alter, Call, Cancel, Close, Compute, Delete, Disable, Display, Divide, Enable, Enter, Exit, Generate, GoTo, If, Initiate, Inspect, Merge, Move, Multiply, Open, Perform, Read, Receive, Replacing, Return, Rewrite, Search, Send, Set, Sort, Start, Stop, String, Subtract, Suppress, Terminate, Unstring, Use_After, Use_For_Debugging, Write
If only COBOL had the verbs 'publish', 'subscribe' and 'transform' ... then it we could have called it the 'COBOL-ESB' ;-)
Friday, April 02, 2004
Tech question...
I've run across a number of web service operations that look like 'foreign-key' relationships.
As an example, look at the following web service operations:
getTeams() // returns a list of all teams, including all the team id's
getPlayers(teamID) // returns a list of players, for a specific team id
Now, this seems intuitive for a human to figure out - call getTeams(), and then use the key to make a call to getPlayers(theKey) for the team you want. However, this isn't intuitive for a computer to figure out. When you are in an interactive setting (InfoPath, Excel, etc.), and you make a call to getPlayers(..), you want the software to give you a drop-down list of all of the teams. But in order for this to happen, the software (Excel or whatever), needs to know about the relationship between the two operations (getTeams and getPlayers). This information is usually capture at the DB level and is also captured at the object level (UML), but I don't see a mechanism to publish this type of relationship at the service level.
So, here is my question: How do I define and publish computer-readable operation-to-operation relationships using a standardized metadata description language (like WSDL, or other)? Email me: jschneider at momentumsoftware dot com
As an example, look at the following web service operations:
getTeams() // returns a list of all teams, including all the team id's
getPlayers(teamID) // returns a list of players, for a specific team id
Now, this seems intuitive for a human to figure out - call getTeams(), and then use the key to make a call to getPlayers(theKey) for the team you want. However, this isn't intuitive for a computer to figure out. When you are in an interactive setting (InfoPath, Excel, etc.), and you make a call to getPlayers(..), you want the software to give you a drop-down list of all of the teams. But in order for this to happen, the software (Excel or whatever), needs to know about the relationship between the two operations (getTeams and getPlayers). This information is usually capture at the DB level and is also captured at the object level (UML), but I don't see a mechanism to publish this type of relationship at the service level.
So, here is my question: How do I define and publish computer-readable operation-to-operation relationships using a standardized metadata description language (like WSDL, or other)? Email me: jschneider at momentumsoftware dot com
Subscribe to:
Comments (Atom)